Twinfolio: an open-source portfolio that answers as you
Twinfolio is the open-source engine I pulled out of this site: a personal portfolio that chats as you, grounded in your real work — built by talking to it, with no database and one API key.

People keep asking me the same thing after they talk to the chat on this site: how do I build one for myself? The honest old answer was "clone my repo and delete all the parts about me," which is a terrible answer. So I pulled the engine out into its own project. It's called Twinfolio — the same stack running this site, generalised so it isn't about me — and this is the honest version of what it is, the engineering worth a look, and how you deploy your own in minutes.
What an AI portfolio actually is
A normal portfolio is a brochure. You write it once, it goes stale, and the reader scans the headlines for thirty seconds. An AI portfolio is a conversation: the reader asks the thing they actually care about — "have you shipped anything with evals?", "what's your hardest project?" — and gets a grounded answer, in your voice, with citations to the real material.
That inverts who does the work. A brochure makes the reader guess which of your projects matters to them. A twin lets them ask, and answers from documents rather than from whatever a model imagines about your job title.
It's polyglot, too — something I under-sold until I watched it happen. The interface ships in 40 languages, and because the brain is a model rather than a template, the twin follows the visitor's language: flip the site to French and Tesla answers in French, citations intact, even though every source document is in English. The stays in whatever language you wrote it; retrieval doesn't care.
One thing up front, because it's the whole pitch: Twinfolio is the engine, and darrenhead.com is its live reference twin — the public demo, not a site that imports Twinfolio as a dependency. They're sibling Next.js codebases that share a lineage, and the extraction direction is site → engine. A clarification I owe you: the live darrenhead.com is a larger Supabase-backed app with a database. The "no database" property below is Twinfolio-the-engine's, not this site's.
The wedge: talk to it
Here's the part that's genuinely different. Every other "chat with a personal " project assumes you arrive with a clean corpus to upload. Most people don't have one. Twinfolio flips that: the twin interviews you.
You open a short self-interview — by voice or by text — and it asks about your work like a sharp friend who wants the real story: roughly eight to twelve warm, one-at-a-time questions across a few themes, favouring follow-ups over yes/no. You can paste a link and a read_url tool fetches and summarises the page. When you're done, a pipeline turns the conversation into your knowledge base:
capture → normalize → proper-noun pass → distill → write → re-index
distillTranscript rewrites your answers into first-person markdown (a faithful reorganisation, not a creative rewrite), a proper-noun pass fixes a glossary, and mergeIntoProfile folds it all into a single canonical content/profile.md where newer answers win on conflict. Role and bio edits aren't auto-applied — the twin proposes them and you confirm. The promise in the README is that you can have written nothing and still end up with a citeable AI twin in about ten minutes.
The voice path runs on — an ephemeral, single-use token is minted server-side so your real key never reaches the browser, with 16 kHz PCM up / 24 kHz down, , and session resumption so a dropped connection reconnects transparently. The text path runs on the same model brain as the chat. Either way, the corpus is something you talk into existence.
To be fair about it: uploading is also first-class. A second deployment I built to prove the template generalises built its corpus by dropping in a CV PDF, not by interviewing. The interview is the marquee flow, not the only one.
No database: "git is the database"
This is Twinfolio's technical soul, and the cleanest engineering story in it. A deployed personal site with admin editing, a CMS, and RAG — and zero database to provision.
Three plain files are the source of truth:
twinfolio.json— persona, site, models, usage caps, projects (and even an inline base64 avatar; on the second deploy the headshot is literally a string in the tracked JSON).app/theme.css— only the:rootand.darktoken blocks.content/— the RAG corpus: markdown, PDFs, text, images, plus the distilledprofile.md.
The /admin Studio edits these through a swappable ConfigStore seam. In local dev, FileConfigStore writes the files directly. Deployed, GitHubConfigStore commits twinfolio.json / theme.css straight to your repo via the Contents API — which triggers a Vercel redeploy. That's the whole "no database" trick.
The hard part is that a filesystem is read-only at runtime, so a live site can't just write its own files. Twinfolio's corpus write ladder (lib/corpus/persist-file.ts) tries, in order, and never throws:
- — runtime-writable, re-indexes live with no redeploy.
- Git commit — redeploys, lands in about a minute.
- Dev filesystem.
- Nothing writable → hand you the markdown to commit by hand.
There's a subtler bug I'm glad I caught: because each save commits the whole file, GitHubConfigStore reads config from the repo tip on every editor read, not from the build-time bundle — otherwise editing from a stale snapshot would silently erase commits that landed since this deploy, including your own previous save still redeploying. The corpus read is tip-aware the same way. The HELP.md documents the "my admin edit disappeared after a deploy" symptom honestly, because it's a real failure mode if you get this wrong.
Visitor chat history? Browser localStorage — explicitly the no-database replacement for this site's Supabase persistence. Usage caps default to in-memory per-instance windows, optionally backed by Upstash Redis for exact cross-instance counts.
One OpenRouter key = a complete twin
Setup cost collapses to almost nothing because a single key does double duty. is the brain: lib/ai/openrouter.ts builds the provider with HTTP-Referer / X-Title from your config so traffic is attributed to your deployment, and getChatModel() resolves whatever model id you set (free models are explicitly endorsed). The same key embeds the default RAG.
And the default RAG is local vectors, not a managed service. npm run embed chunks your markdown, text-extracts PDFs via unpdf, and — since OpenRouter can't embed images — captions images with a vision model and embeds the caption. Everything lands in one JSON file, content/.vectors.json (1536-dim, openai/text-embedding-3-small). At query time the backend embeds the query once and runs in-memory top-K — no LLM in the retrieval path, no vector DB to babysit, so retrieval stays fast by design. Gemini File Search exists as an optional managed backend for Office docs and large corpora, but local vectors are the default.
The billing safety is its own load-bearing module — lib/ai/model-chain.ts, commented "this is the money path." allow_fallbacks defaults off, so a free or cheap default can never silently bill through a paid fallback; fallbacks are tier-matched, and every call is output-token-capped so a provider can't pre-authorise a huge budget and fail on a low-balance or BYOK account. That one line — a free default never silently routing to a paid model — is the difference between an open-source toy and something you'd point at the public internet.
The voice itself is grounded but honest. The forces first person, injects a numbered CONTEXT block, and hard-rules the model: ground every claim in the retrieved context, never invent employers, dates, or numbers, and when the context doesn't cover the question, say so and offer to connect rather than guess. Citations stream first, as data-citation parts, so the source strip renders before the text does.
Demo-mode-first, then make it yours
Friction at "step zero" is where open-source projects lose people, so the default path is "it runs": a fresh clone runs end-to-end with zero keys. With no key, the chat streams a friendly canned reply through the real stream — so the UI is genuinely functional — and retrieval degrades to persona-only answers rather than throwing. That's a hard requirement in the code, not a nicety.
There are two onboarding doors. A GUI wizard at /welcome (Identity → Branding → Models & keys → Knowledge → Go live), and bundled Claude Code agent skills — /setup-twin, /add-to-corpus, /retheme, /deploy, /add-vector-db — that any agent can run via AGENTS.md. Skills are just prompts; opening the repo runs nothing until you act.
A detail I'm quietly proud of: every shipped sample file carries an HTML-comment sentinel, {/* twinfolio:sample */}, and the index builder excludes sentinel-marked docs. So the example persona's bio can never bleed into a real twin's retrieval, even in the onboarding preview, even before you clear it. Your first real save deletes the samples.
The adapter spine and the Theme Studio
The architecture that makes "no database," "pick your RAG," and "make it look like you" all true at once is what CLAUDE.md calls the adapter spine: one Studio over two swappable seams. ConfigStore decides where config persists (File or GitHub); RagBackend decides how retrieval happens (local vectors, Gemini File Search, or none). getConfigStore() and getRagBackend() are the factories — nothing else in the app assumes where the vectors live. RagBackend is a tiny two-method interface, which is why the /add-vector-db skill can scaffold a pgvector or Pinecone adapter behind the same seam in a fork without touching core.
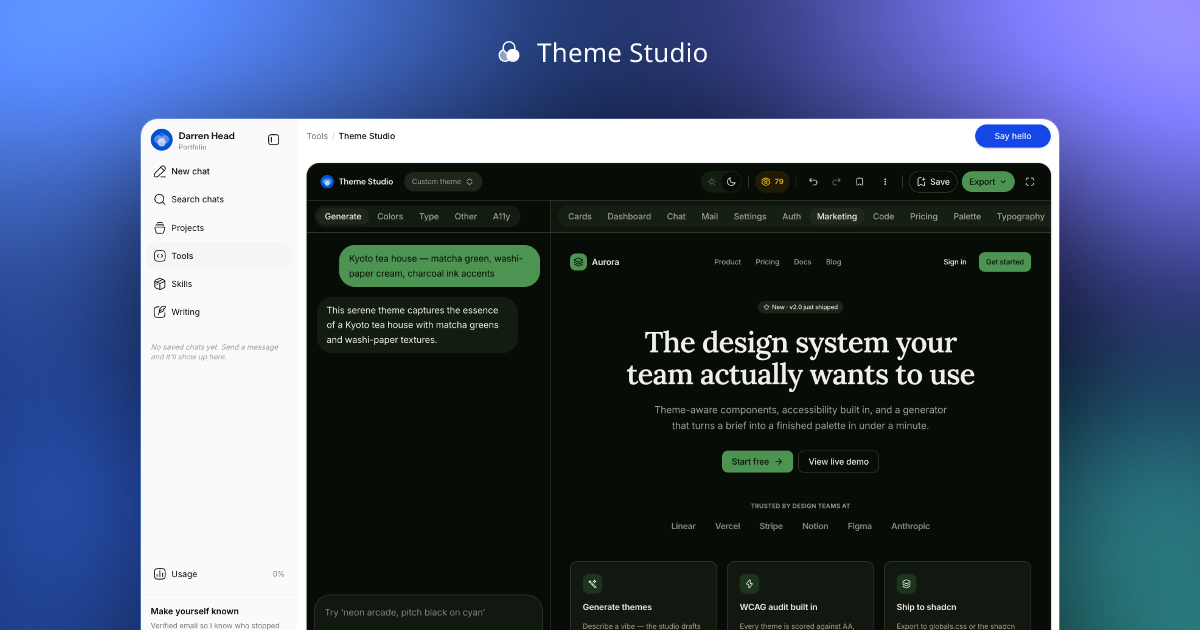
The most demoable surface is the Theme Studio — a no-code live oklch token editor lifted from this site's own design system. About 32 colour tokens per mode, plus radius, fonts, and a six-step shadow scale, all driven from app/theme.css. A contrast engine (ported from here, using culori) audits roughly 16 token pairs per mode, composites translucent foregrounds before scoring, and an auto-fix nudges only the oklch lightness channel until each pair clears AA. A "Copy globals.css" button lifts the theme into any / Tailwind-v4 project.
What it is not — and the licence
I'll be straight about scope. Twinfolio is not a CRM or lead-capture tool. It's not for interviewing other people — it interviews you, to build your twin. It's not a clone, companion, or deepfake; it's always legibly an AI version of me, trained on my work. It's not an ATS screener, and it's not a hosted SaaS. It's a free thing you deploy yourself. Provided as-is, no support, no guarantees — fork freely.
Twinfolio is . The LICENSE is the GNU Affero GPL v3 and package.json declares AGPL-3.0-or-later. The practical meaning: if you run a modified version as a network service, you offer your source under the same licence. For a project whose whole premise is grounding claims in reality, shipping the engine open — and being honest about its licence — is the consistent move.
Deploy your own
The deploy is the easy part. The corpus is the real work, and now you don't even have to write it from scratch — you can just talk to it.
git clone https://github.com/darrenhead/twinfolio.git twinfoliocd twinfolionpm installnpm run dev # http://localhost:3000, /welcome wizard, ZERO keys needed
Make it yours through the wizard (or /setup-twin), then go live: the wizard publishes to your own new GitHub repo and keeps Twinfolio as upstream, so engine updates pull cleanly. Import at vercel.com/new, set OPENROUTER_API_KEY (real chat + the build-time embed — needed before the first build) and ADMIN_TOKEN (openssl rand -hex 32; gates /admin, fail-closed in prod). Then in the live /admin → Deploy, click Connect GitHub — a , no PAT, no callback URL — so Studio saves commit and redeploy.
If you've ever wanted a portfolio that answers for you, that's the whole loop: clone it, talk to it, ship it. The engine is open at github.com/darrenhead/twinfolio — feed it your story.